Elasticsearch에서 분산모델2(Distributed Model)
이전에 마스터와 세컨드 노드를 간단히 추가해보았다. 그리고 노드가 추가되면 마스터가 가지고 있는 클러스트 상태정보는 추가되는 슬레이브 노드에게 전달된다. 그리고 이 클러스트 상태 (Cluster State)에는 샤드(Shard)정보를 가지고 있다. 그럼 샤드는 무엇인가?
1. 샤드(Shard) 그리고 리플케이션(Replication)
엘라스틱에서 데이터는 샤드단위로 저장이 이루어진다. 단 한개의 노드를 만들더라도 기본적으로 샤드로 구성되어 저장이 된다. 디폴트는 5개이다. 그냥 인덱스를 생성하고 조회하면 다음과 같이 샤드정보가 보인다.
curl -XGET "http://localhost:9200/my_index/_settings"
{
"my_index": {
"settings": {
"index": {
"creation_date": "1521813068040",
"number_of_shards": "5",
"number_of_replicas": "1",
"uuid": "8lh6pLwGTOyoTj7LeKDDSQ",
"version": {
"created": "5060499"
},
"provided_name": "my_index"
}
}
}
}
number_of_shards 부분에 보면 5라고 표시되어 있다. 샤드는 인덱스를 생성할 때 만들어지고 수정이 불가하다. 그러므로 처음부터 신중하게 설정하게 진행해야 한다.
우리가 해당 index안에 document를 넣으면 샤드에 각각 분할되서 저장이 된다. document를 넣을 때 우리는 put, post등을 사용했다. post 메소드를 사용할 경우 document ID는 랜덤하게 생성되서 저장되고 put 메소드를 사용하면 우리가 지정한 ID값을 넣을 수 있다. 바로 ID를 가지고 샤드분할이 이루어진다.
shard = hash(_routing) % number_of_primary_shards
바로 위 공식을 통해서 도큐먼트가 추가될 때마다 해당 사드로 저장이 된다. 위에 _routing이 도큐먼트 id로 보면 된다. 이렇게 샤드를 통해서 데이터를 분할저장하면 대용량을 검색할 때 아주 빠르게 된다.
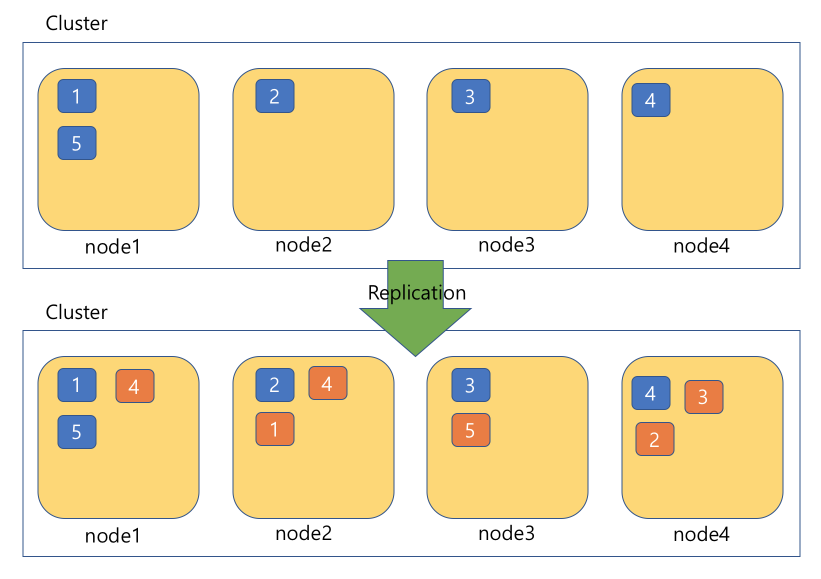
위에 그림을 보자 5개의 document가 추가되면 각각 노드의 샤드별로 저장된다. 이렇게 저장된 document는 클러스트링에 의해서 다른 노드의 샤드들에게 복사본이 생성된다. 이런 복사가 되는 과정을 바로 Replication 이라고 한다. 정리하면 데이터(document)는 Shard로 분할되서 저장되고 Replication은 각각의 Shard에 저장된 데이터를 해당 데이터가 없는 다른 노드에 복사하는 과정을 만든다. 이렇게 되서 만약 노드3이 죽었다면 다른 노드는 노드3이 가지고 있었던 복사본(샤드)을 다른 노드에게 카피한다.
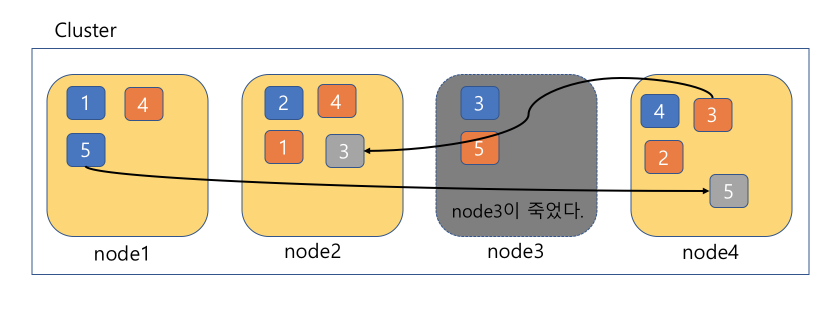
이렇게 어떤 노드가 죽어도 나머지 노드의 정보들 때문에 데이터의 무결성을 유지할 수가 있다. 그렇다면 Replcation갯수는 몇 개가 좋은가?(디폴트는 1개)
최대 Relication 갯수 = 전체 node 수 - 1
즉 최소 1개에서 최대는 반드시 전체 노드보다 작아야 한다.
2. Reindexing
reindexing 무엇일까? 만약 특정인덱스에 PUT를 했을 경우 이미 기존에 같은 document가 있다면, 엘라스틱에서는 기존데이터를 삭제하고 새로 생성한다. 그런데 put를 한다면 reindex를 할때 모든 필드를 입력해야 한다.
curl -XPUT "http://localhost:9200/my_index/doc/1" -H "Content-Type: application/json" -d '
{
"username": "richard",
"comment": "Mt favorite movie is Golira!",
"city": "seoul"
}'
만약 기존 필드는 그대로 두고 특정 필드 몇개만 넣고 싶다면 그때는 post, _update등을 사용하면 된다.
curl -XPOST "http://localhost:9200/my_index/doc/1/_update" -H "Content-Type: application/json" -d '
{
"doc": {
"city": "seoul"
}
}'
반드시 document 이름안에 추가할 필드를 넣어주면 된다.
3. Split Brain
엘라스틱에서 노드는 크게 두가지로 구분할 수 있다. 바로 마스터 노드와 데이터 노드이다.
마스터 노드 : 클러스트의 상태 정보를 관리
데이터 노드 : 데이터의 입력, 출력 및 검색
마스터노드는 클러스트의 상태를 관리하는 중요한 노드이다. 만약 노드가 3개이상 실행된다면 한개는 마스터이고 다른 한개는 데이터노드 그리고 마지막 한개는 마스터 후보 노드가 된다. 문제는 마스터 노드 사이에 연결이 끊어졌을 때 각각의 마스터 후보 노드(master-eligible node)가 각각 마스터 노드로 승격하는 상황이 발생하는 데 이것이 바로 Split Brain 이라는 것이다.
이런 상황을 피하기 위헤서는 마스터 노드를 최소 3개로 하고 더 늘릴 경우에는 반드시 홀수개로 설정해야 한다. 홀수개로 설정하는 이유는 마스터 노드 선출에서 반드시 1개만 설정되기 위해서이다. 설정파일에 보면 다음과 같이 주석처리됨을 알 수 있다 .
# Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1):
#
#discovery.zen.minimum_master_nodes: 3
즉 전체 마스터 후보 노드가 3이라면 3/2 + 1 = 2 로 구성해야 한다는 것이다. 엘라스틱에서는 마스터 후보 노드를 3개로 권장하고 있다.